

背景
今天一个业务系统开发群里的产品经理艾特我和其他几个人,说是帮忙解决一个线上kafka重复消费的问题。问题描述如下:
原本: 生产者P,kafka,消费者C,运行顺利。8月27号发现,C在不停地重复消费8月26号某段时间的消息,新消息不消费,并且P一切正常。
期间,P、Kafka、C都没有做过任何变动(镜像、配置都没有动过)。
然后时间拖到今天,因为重复消费,导致线上系统C已经出现明显数据异常。
每一个技术上的疑难杂症,都是一个绝佳的机会。一旦攻克,就能在技术的迷雾中捅出一个洞来,方能窥见更多的真相。
正好kafka很久没碰,基本还给2018年的自己了。所以,上吧。
调查
“调查就像十月怀胎,解决问题就像一朝分娩。调查就是解决问题” —— 教员
通过和PM的沟通发现,期间,虽然三个系统没有任何变动,但是发生过一次网络问题,具体原因不详,具体影响不详。网络恢复后,出现此次事故。
因此猜想: 会不会是网络问题导致的,这个猜想很笼统,不能更细,因为不了解网络问题的影响和kafka的具体机理。
这个笼统的猜想先记着,放一边。然后去搜kafka的原理和类似“kafka 重复消费”问题:
通过上述资料,基本定位了几个关键词:offset、rebalance 、max.poll.interval.ms、max.poll.records。
然后在群历史记录里找到了C的日志,乍一看没什么问题,没有堆栈信息,甚至ERROR都没有,而且消费日志的确打印了。因为重复消费的时间段跨度较大,群里的这个日志内容较少显示不全,看不出重复消费问题。
但是在上面的文章(《关于一次Kafka重复消费问题排查记录的闲谈》)中,发现了一个日志中值得注意的内容:
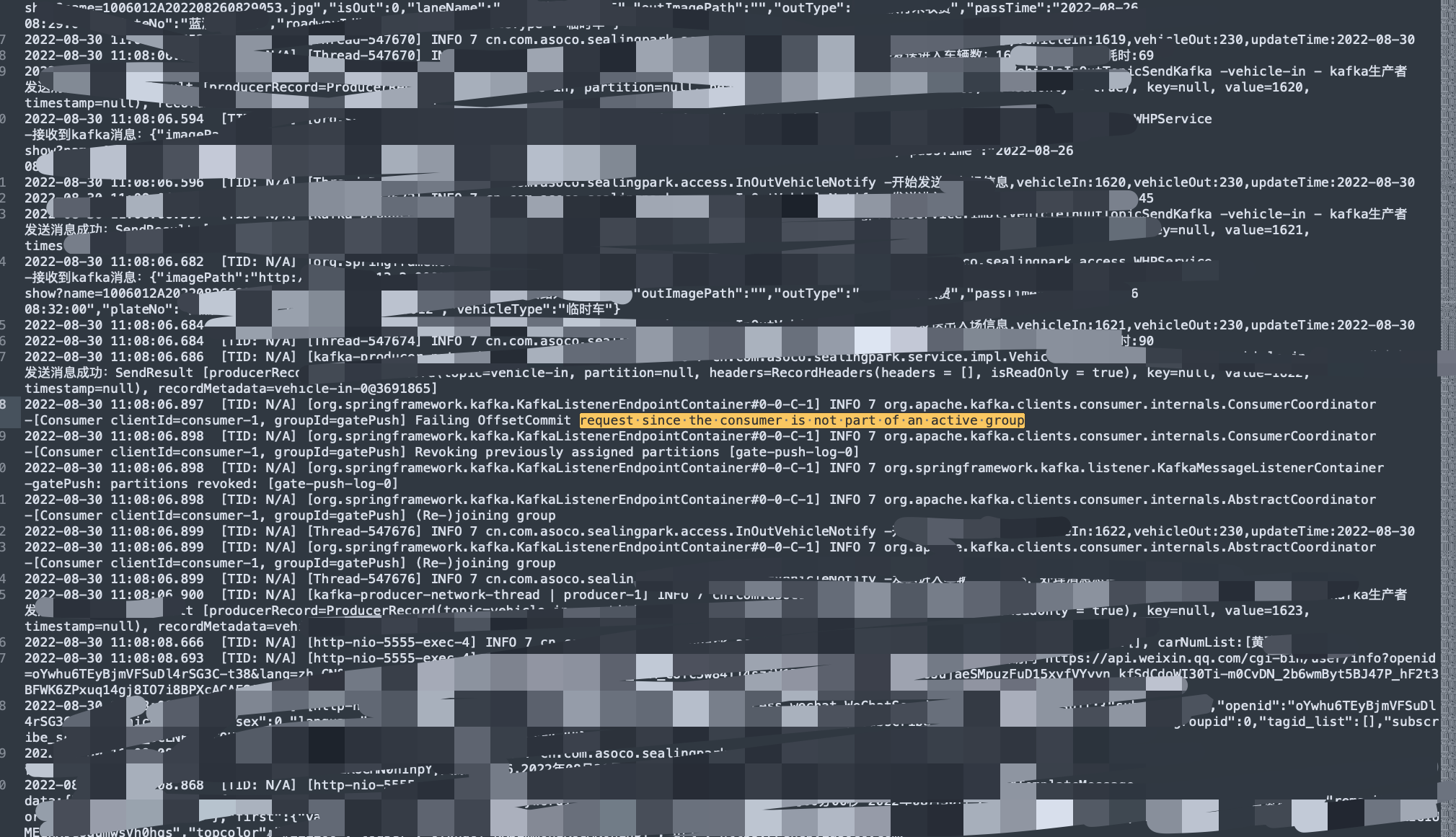
Failing OffsetCommit request since the consumer is not part of an active group
也就是说,消费者接受到消息后,offset提交并没有成功,因为不在消费组里了,被kafka踢掉了,结合上面关键词rebalance。
大致定位了原因: 消费者C正常消费了,但是Offset提交却失败了,因为kafka的rebalance机制,提交失败,导致kafka记录的offset并没有变动,也就是kafka认为C还没消费。当rebalance后,C根据offset值又开始消费重复的消息
那么问题是,为什么会触发kafka的rebalance,从而导致C提交失败呢?
根据另外两个关键词max.poll.interval.ms、max.poll.records,翻阅官方文档, 了解这两个配置项:
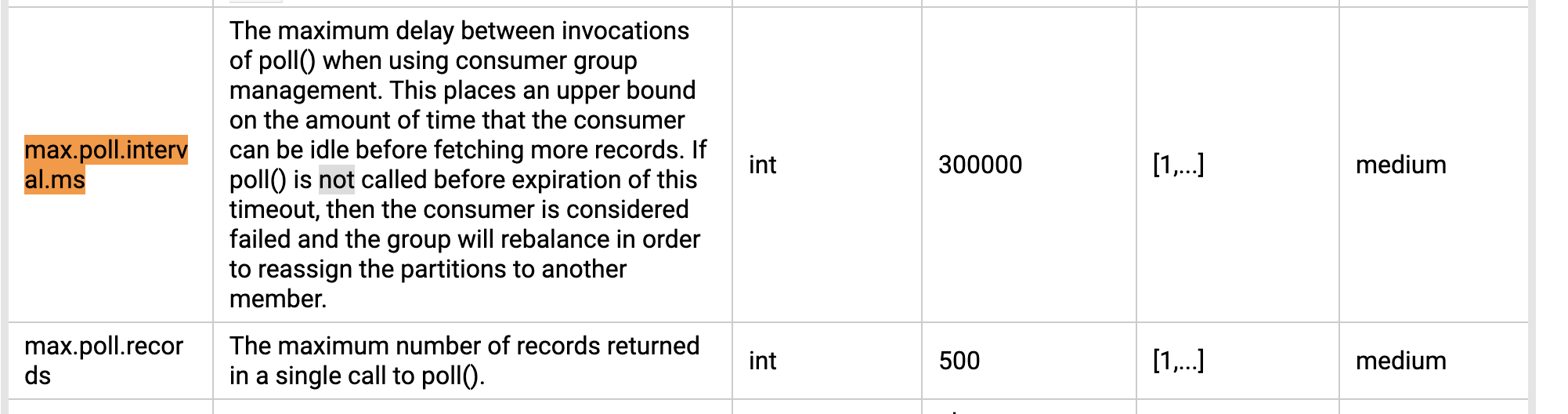
翻译一下:
max.poll.interval.ms: 使用消费者组管理时调用 poll() 之间的最大延迟。这为消费者在获取更多记录之前可以空闲的时间量设置了上限。如果在此超时到期之前未调用 poll(),则认为消费者失败,组将重新平衡,以便将分区重新分配给另一个成员。
max.poll.records: 在一次 poll() 调用中返回的最大记录数。
消化一下,自己的理解是:
max.poll.interval.ms: 消费者接收到一组消息时的最大处理时间。超过了,会触发rebalance。
max.poll.records: 消费者接收的一组消息中的最大消息数量。
结合起来说,就是C每次最多收到500条(默认值)消息,在300000毫秒(默认值)内如果能消化掉,并发送poll(也就是ACK),那么就正常,否则会触发rebalance, 触发的后果上面已经说了,不赘述。
解决
到这里,基本问题就解决了,配置这两个值即可。最后我提供的值是:
spring.kafka.consumer.properties.max.poll.interval.ms: 200000
spring.kafka.consumer.properties.max.poll.records: 100
因为是spring-kafka,所以配置项有前缀
问题得到解决。
复盘
回到前面的那个笼统的猜测:会不会是网络问题导致的。结合上面的调查过程,可以把这个猜想进一步细化:
会不会是网络问题导致: 消费者和kafka中断,但是生产者依旧在产生消息,从而在Kafka堆积消息。当网络恢复后,消费者一次消费到500条消息,而因为限制的时间是300000毫秒,导致超时,从而触发rebalance, Offset commit 提交失败,rebalance后,offset又从之前的地方开始读,从而导致重复读取26号的数据。
至于猜想的验证,得有更多的投入和条件才行啊。。。
对于消费的过程,看到一个比喻还是比较形象的:
工头(
kafka)命令每个码农(consumer)最多10分钟(max.poll.interval.ms)把一批100(max.poll.records)块砖运到目的地并用来垒房子(业务系统收到消息后的处理),然后回来接着取砖、垒房子。问题在于,你搬了100块砖走了,但是10分钟过去了,你还没回来,那工头怎么知道你是不是偷懒睡觉去了,工头就把这个搬砖垒房子的活分给同在一起干活的其他人了(同group不同consumer)。其实你可能没有偷懒,是因为你太追求完美了(估计是处女座,或是垒自家的房子),垒房子的时间很长(spending too much time message processing),10分钟内没能回来向工头报道,这时,你就得和工头商量,两种办法:
1、能不能15分钟内回来就行(延长max.poll.interval.ms)
2、10分钟内回来,但每次搬80块砖来垒房子。(减少max.poll.records)
如果老板是个比较有控制欲的人,对于第二种办法,同样的工作量,你无非是多跑几趟。还能很好的控制你;但是对于第一种办法,老板是不愿意的,为什么,因为和你一起搬砖的还有其他人,他可以协调(rebalance)其他5分钟就回来的人来干你的活。你告诉他15分钟对于工头来说是相对不可控的。
当然你还有另一种办法,你可以找你儿子来搬砖(另起一个线程, 异步,),你来垒房子,当你开始用100块砖垒房子时,就让你儿子去告诉工头已经开始垒了, 工头在本本(offset)上记录这100块砖已经被正常用了(正常消费了),你儿子转身就搬回下一个100块砖。
这种异步方式需要注意一个问题,就是你儿子不能在你还没有垒完上100块砖就搬回了下一批100块转。这样你就处理不过来了。
继续?
另外,在消费者C的源码内置配置中,发现一个配置项:
spring.kafka.consumer.auto-offset-reset: earliest
如果是别的值,会不会策略是不重连,而是丢掉消息,继续消费?